Install and Configure OpenStack Mitaka with GlusterFS on CentOS 7
![]()
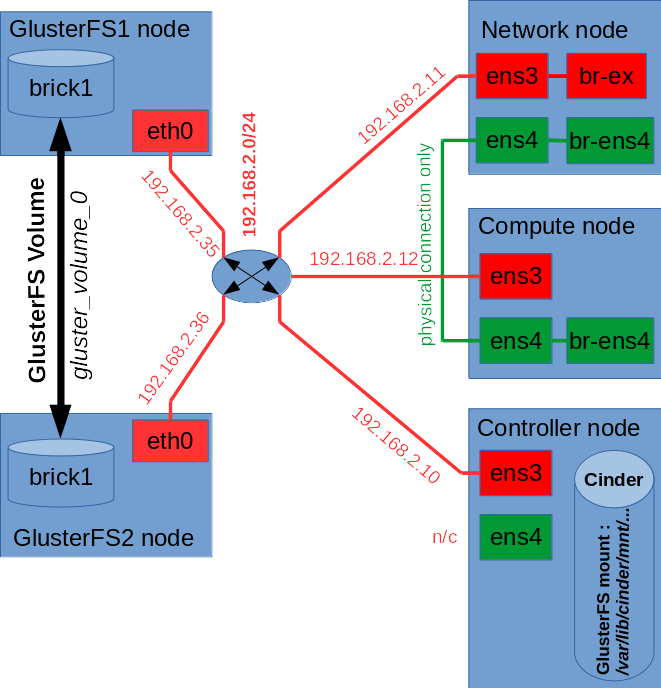
OpenStack can use diffirent backend technologies for Cinder Volumes Service to create volumes for Instances running in cloud. The default and most common backend used for Cinder Service is LVM (Logical Volume Manager), but it has one basic disadventage – it’s slow and overloads the server which serves LVM (usually Controller), especially during volume operations like volume deletion. OpenStack supports other Cinder backend technologies, like GlusterFS which is more sophisticated and reliable solution, provides redundancy and does not occupy Controller’s resources, because it usually runs on separate dedicated servers.
In this tutorial we are going to deploy VLAN based OpenStack Mitaka on three CentOS 7 nodes (Controller, Network, Compute) using Packstack installer script and integrate it with already existing GlusterFS redundant storage based on two Gluster Peers.